安装
转发 IPv4 并让 iptables 看到桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system通过运行以下指令确认 br_netfilter 和 overlay 模块被加载:
lsmod | grep br_netfilter
lsmod | grep overlay通过运行以下指令确认 net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables 和 net.ipv4.ip_forward 系统变量在你的 sysctl 配置中被设置为 1:
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward临时关闭swap分区
sudo swapoff -a
# Debian永久关闭
systemctl --type swap --all
systemctl mask dev-xxx.swap配置cgroup驱动
# 备份/etc/containerd/config.toml
containerd config default > /etc/containerd/config.toml
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"安装 kubeadm、kubelet 和 kubectl
# 基于Red Hat的发行版
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 此操作会覆盖 /etc/yum.repos.d/kubernetes.repo 中现存的所有配置
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
sudo systemctl enable --now kubelet
# 基于Debian的发行版
sudo apt-get update
# apt-transport-https 可能是一个虚拟包(dummy package);如果是的话,你可以跳过安装这个包
sudo apt-get install -y apt-transport-https ca-certificates curl
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl添加指令补全
sudo apt-get install bash-completion
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc
cat ~/.bashrc初始化Master节点
控制平面节点是运行控制平面组件的机器, 包括 etcd(集群数据库) 和 API 服务器 (命令行工具 kubectl 与之通信)。
- 如果计划将单个控制平面 kubeadm 集群升级成高可用, 你应该指定
--control-plane-endpoint为所有控制平面节点设置共享端点。 端点可以是负载均衡器的 DNS 名称或 IP 地址。 - 选择一个 Pod 网络插件,并验证是否需要为 kubeadm init 传递参数。 根据你选择的网络插件,你需要设置 --pod-network-cidr 的值。
--apiserver-advertise-address选项用于指定API服务器(kube-apiserver)公开给集群成员的地址,它指定了Master节点上kube-apiserver进程所使用的网络地址,用于与其他节点和客户端通信。
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address=10.1.1.33 --control-plane-endpoint=10.1.1.33 --pod-network-cidr=192.168.0.0/16
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address=10.1.1.33 --control-plane-endpoint=10.1.1.33 --pod-network-cidr=10.244.0.0/16
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address=192.168.8.99 --control-plane-endpoint=192.168.8.99 --pod-network-cidr=10.2.0.0/16[init] Using Kubernetes version: v1.27.1
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
W0417 13:53:10.500146 787361 images.go:80] could not find officially supported version of etcd for Kubernetes v1.27.1, falling back to the nearest etcd version (3.5.7-0)
W0417 13:53:10.689988 787361 checks.go:835] detected that the sandbox image "registry.k8s.io/pause:3.6" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "registry.aliyuncs.com/google_containers/pause:3.9" as the CRI sandbox image.
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [dev-33 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.1.1.33]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [dev-33 localhost] and IPs [10.1.1.33 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [dev-33 localhost] and IPs [10.1.1.33 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
W0417 13:53:18.875118 787361 images.go:80] could not find officially supported version of etcd for Kubernetes v1.27.1, falling back to the nearest etcd version (3.5.7-0)
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 7.003124 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node dev-33 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node dev-33 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: vxma82.htnutqlrk5ogk4jt
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 10.1.1.33:6443 --token vxma82.htnutqlrk5ogk4jt \
--discovery-token-ca-cert-hash sha256:a33deba545a4ea70d612cd828954d3c8c33e8554a2763d5148f587e5c29830bd \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.1.1.33:6443 --token vxma82.htnutqlrk5ogk4jt \
--discovery-token-ca-cert-hash sha256:a33deba545a4ea70d612cd828954d3c8c33e8554a2763d5148f587e5c29830bd 部署Node节点
kubeadm join 10.1.1.33:6443 --token n826db.gaagqa112dpjbs0p \
--discovery-token-ca-cert-hash sha256:3a93c6c6c752ee40dfd8e5e9be8bd442ee350b5114bc9ec16cede4c234b656d7 排查指令
journalctl -xefu kubelet
journalctl -xefu containerdIngress控制器
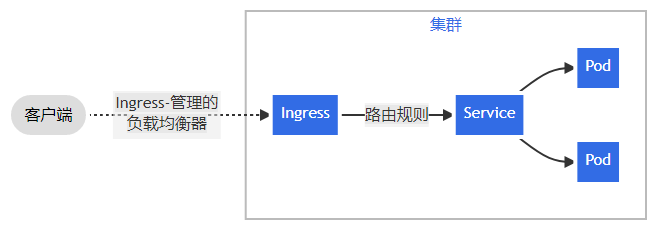
Ingress 公开从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
添加kuboard
docker run -d \
--restart=unless-stopped \
--name=kuboard \
-p 80:80/tcp \
-p 10081:10081/tcp \
-v ./:/data \
-e KUBOARD_LOGIN_TYPE="ldap" \
-e KUBOARD_ENDPOINT="http://10.1.1.33:80" \
-e KUBOARD_AGENT_SERVER_TCP_PORT="10081" \
-e KUBOARD_ROOT_USER="xxxxx" \
-e LDAP_HOST="ipa.xxxxxx.cn:636" \
-e LDAP_SKIP_SSL_VERIFY="false" \
-e LDAP_BIND_DN="uid=xxx,cn=users,cn=accounts,dc=xxx,dc=cn" \
-e LDAP_BIND_PASSWORD="xxxxxxxx" \
-e LDAP_BASE_DN="dc=xxxxxx,dc=cn" \
-e LDAP_FILTER="(uid=%(user)s)" \
-e LDAP_ID_ATTRIBUTE="uid" \
-e LDAP_USER_NAME_ATTRIBUTE="uid" \
-e LDAP_EMAIL_ATTRIBUTE="mail" \
-e LDAP_DISPLAY_NAME_ATTRIBUTE="displayname" \
-e LDAP_GROUP_SEARCH_BASE_DN="cn=groups,cn=accounts,dc=xxx,dc=cn" \
-e LDAP_GROUP_SEARCH_FILTER="(objectClass=groupOfNames)" \
-e LDAP_USER_MACHER_USER_ATTRIBUTE="memberOf" \
-e LDAP_USER_MACHER_GROUP_ATTRIBUTE="member" \
-e LDAP_GROUP_NAME_ATTRIBUTE="cn" \
eipwork/kuboard:v3管理后续节点
添加master节点
调整ectd为单节点模式
etcd 启动失败是由于 etcd 在 3 节点集群模式在启动却无法连接另外 2 台 master 节点的 etcd ,要解决这个问题需要改为单节点集群模式。开始不知道如何将 etcd 改为单节点模式,后来在网上找到 2 个参数 --initial-cluster-state=new 与 --force-new-cluster ,在 /etc/kubernetes/manifests/etcd.yaml 中给 etcd 命令加上这 2 个参数,并重启服务器后,master 节点就能正常运行了。# 获取token和token证书
kubeadm token create --print-join-command
kubeadm join 10.1.1.33:6443 --token py3msf.sy2inpdw1z17247r --discovery-token-ca-cert-hash sha256:be0a7aa7640f735c57c3d282453f4fc047804feee6be68b7604267b8149bdbc7
# 获取control-plane证书
sudo kubeadm init phase upload-certs --upload-certs
I0907 14:19:25.567659 2491954 version.go:256] remote version is much newer: v1.28.1; falling back to: stable-1.27
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
abb6b151b79156887cb415c7fd3b3af653b4b26f4da3c6dfb93c3d7c41b25867
# master节点执行命令
sudo kubeadm join 192.168.255.100:6443 --token peawzl.bwonk5nviow72m9g \
--discovery-token-ca-cert-hash sha256:be0a7aa7640f735c57c3d282453f4fc047804feee6be68b7604267b8149bdbc7 \
--control-plane --certificate-key abb6b151b79156887cb415c7fd3b3af653b4b26f4da3c6dfb93c3d7c41b25867
添加node节点
# 获取master节点的join token
kubeadm token create --print-join-command
kubeadm join 10.1.1.33:6443 --token py3msf.sy2inpdw1z17247r --discovery-token-ca-cert-hash sha256:be0a7aa7640f735c57c3d282453f4fc047804feee6be68b7604267b8149bdbc7
# 在Node节点上执行join指令给node节点打标签
# 获取节点详情
kubectl get nodes -o wide --show-labels=true
# 添加节点标签
kubectl label nodes xxxx labelname=labelvalue
# 使用nodeselector进行pod的调度使POD调度到Master节点
在部署yaml文件中添加能够容忍的污点配置
kubectl describe node bj-8-105使用该指令找到Taints字段填充下方yaml配置中的key
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane配置解释
Service
- port:集群内服务访问的service入口,service暴露在Cluster上的端口;集群内部节点可以通过该端口访问该服务,但是外部网络不能够访问到服务;
- targetPort:容器的端口,最底层服务提供的端口,相当于pod的端口;从port或者nodePort进入的流量,经过路由转发之后最终都会通过targetPort进入到pod中;
apiVersion: v1
kind: Service
metadata:
name: xxx-community-frontend-hk
spec:
type: NodePort
selector:
app: xxx-community-frontend-hk
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- nodePort: 30003 # 外部访问的端口
port: 3230 # 容器间,服务调用的端口
protocol: TCP # 协议
targetPort: 3230# 容器暴露的端口,与Dockerfile暴露端口保持一致Deployment
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: stringConfigMap
- ConfigMap 可以作为数据卷挂载。ConfigMap 也可被系统的其他组件使用, 而不一定直接暴露给 Pod;
- 当卷中使用的ConfigMap被更新时,所投射的键最终也会被更新;但是以环境变量方式使用的ConfigMap数据不会被自动更新,更新这些数据需要重新启动Pod;
- 对于大量使用ConfigMap的集群,可以使用不可变更的ConfigMap;一旦配置文件被标记为不可变更,则无法逆转这一变化,也无法更改data或binaryData字段的内容;
Secret
- 每个文件最多为1MB,避免用户创建非常大的Secret,进而导致内存耗尽,所以推荐使用资源配额来约束namespace中的个数;
Label
kubectl get nodes --show-labels
# 给节点打标签
kubectl label nodes <your-node-name> ramnum=32apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
ramnum: 32
# 使示例容器调度到指定节点上 CPU/RAM分配
CPU
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"
# 配置文件的 args 部分提供了容器启动时的参数。 -cpus "2" 参数告诉容器尝试使用 2 个 CPU
# 一个容器的 CPU 请求为 500 milliCPU,并且 CPU 限制为 1 个 CPURAM
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
# 请求100MiB内存 并且内存会被限制在200MiB内
# 超过容器限制内存:内存溢出被杀掉
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 24s
# 超过整个节点的内存:不会被调度到任何节点上运行,无限期保持此状态
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
No nodes are available that match all of the following predicates:: Insufficient memory Containerd
配置私有镜像仓库
https://github.com/containerd/cri/blob/master/docs/registry.md
vim /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".registry.configs]
#内部私有仓库认证信息
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry.xxx.com"] # 这行不确定要不要写上
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry.xxx.com".tls]
insecure_skip_verify = false # 是否跳过证书认证
ca_file = "/etc/containerd/registry.xxx.com/1_registry.xxx.com_bundle.crt" # CA 证书
cert_file = "/etc/containerd/registry.xxx.com/1_registry.xxx.com_bundle.crt" # harbor 证书
key_file = "/etc/containerd/registry.xxx.com/2_registry.xxx.com.key" # harbor 私钥
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry.xxx.com".auth]
username = "jenkins" # 在harbor里单独创建的用户,授权访问指定项目
password = "new2020!Ceasia#"配置镜像仓库secrets
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/pull-image-private-registry/
# 创建(namespace必须在创建时准确指定)
kubectl create secret docker-registry SECRETNAME \
--docker-server= \
--docker-username= \
--docker-password= \
--docker-email= \
-n NAMESPACE
# 使用
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: your-private-image
imagePullSecrets:
- name: SECRETNAME指令
- 检查证书何时过期:
kubeadm certs check-expiration - 检查kubectl已知的位置和凭证:
kubectl config view - 检测命令或者yaml文件是否正确参数:
--dry-run=client,不生效deployment同时导出yaml文件:--dry-run=client -o yaml - 更新Deployment:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1或kubectl edit deployment/nginx-deployment - Deployment修订历史:
kubectl roolout history xxx
踩坑
执行crictl images报错: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory"
# 因为使用的是containerd.service 需要指定k8s的container runtime
crictl config runtime-endpoint unix:///var/run/containerd/containerd.sockfailed to get sandbox image "registry.k8s.io/pause:3.6"
kubeadm init设置的镜像地址不会传递给cri运行时去下载pause镜像,修改/etc/containerd/config.toml文件中sandbox的镜像地址为sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"或者打tag
crictl pull registry.aliyuncs.com/google_containers/pause:3.6
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.6 registry.k8s.io/pause:3.6运行kubeadm报错:container runtime is not running: output: time="2023-04-14T14:43:13+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint "unix:///var/run/containerd/containerd.sock": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
#修改配置
vim /etc/containerd/config.toml
# Copyright 2018-2022 Docker Inc.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#disabled_plugins = ["cri"]
#root = "/var/lib/containerd"
#state = "/run/containerd"
#subreaper = true
#oom_score = 0
#[grpc]
# address = "/run/containerd/containerd.sock"
# uid = 0
# gid = 0
#[debug]
# address = "/run/containerd/debug.sock"
# uid = 0
# gid = 0
# level = "info"
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"crictl报错
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
E1124 15:59:57.619574 2290376 remote_image.go:171] "PullImage from image service failed" err="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory\"" image="registry.xxx.com/ceasia_test/sk-biz-eureka:20231124152125"
FATA[0000] pulling image: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory"
crictl config runtime-endpoint unix:///var/run/containerd/containerd.sockkubeadm初始化后kube-apiserver无限重启
# 备份/etc/containerd/config.toml
containerd config default
# 将上述指令输出的配置覆盖到config.toml中为什么pod默认不被调度到master上
kubectl describe node dev-33
Taints: node-role.kubernetes.io/control-plane:NoSchedule
# 默认配置了污点ruby就绪探针
要在Rails框架中对使用Ruby后端服务的Kubernetes就绪探针进行配置,请按以下步骤操作:
- 在Gemfile文件中添加 k8s.io gem:
gem 'kubernetes-deploy','~>1.1.0.beta2'
- 运行以下命令启用Rails应用程序中的kubernetes-deploy gem:
bundle install
- 更新您的Kubernetes部署YAML文件以包括就绪探针配置:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-deployment
spec:
replicas: 2
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
containers:
- name: app-container
image: app-image
ports:
- containerPort: 3000
readinessProbe:
httpGet:
path: /health
port: 3000
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 2
successThreshold: 1
failureThreshold: 3
- 在Rails应用程序中定义一个
/health端点,就绪探针可以使用它来检查后端服务是否准备就绪。在Rails中,您可以在routes.rb文件中定义此端点,示例如下:
get '/health', to: 'health#check'
在health_controller.rb文件中,定义一个返回成功状态的操作,如果后端服务准备就绪,则为:
class HealthController < ApplicationController
def check
status = :ok
render json: { status: status }, status: status
end
end
- 将更改部署到Kubernetes,并使用
kubectl监视就绪探针状态:
kubectl get pods
就绪探针状态可以在 READY 列中看到。一旦后端服务准备就绪,状态值将从 0/2 更改为 2/2。
注意:YAML文件中的 initialDelaySeconds、periodSeconds、timeoutSeconds、successThreshold 和 failureThreshold 参数可以根据应用程序的需要进行调整。
初始化ingress-nginx报错cni0" already has an IP address different from 10.2.1.1/24
sudo ifconfig cni0 down
sudo ip link delete cni0概念
核心组件
- CoreDNS(Core Domain Name System):
- CoreDNS是Kubernetes中的一个插件式DNS服务器,用于服务发现和名称解析。
- 它管理集群内部的DNS记录,以便将服务名称解析为相应的IP地址。
- etcd:
- etcd是Kubernetes的分布式键值存储系统,用于存储集群的状态信息。
- 它存储了有关节点、Pod、服务和其他资源的信息,以及它们的配置和状态。
- etcd确保集群中所有组件之间的一致性和可靠性,并提供了高可用性的数据存储。
- API Server(API服务器):
- API Server是Kubernetes的核心组件之一,作为集群的控制面和所有组件之间的通信接口。
- 它提供了用于管理和操作集群资源(如Pod、服务、节点等)的RESTful API接口。
- API Server负责验证和处理来自用户或其他组件的API请求,并将其转发到适当的组件进行处理。
- Controller Manager(控制器管理器):
- Controller Manager是一组控制器的集合,负责监控集群的状态并根据预定义的规则自动管理集群。
- 它包含多个控制器,例如Replication Controller、Deployment Controller和Namespace Controller等。
- 控制器管理器确保集群中的实际状态与期望状态一致,并根据需要采取适当的操作。
- Proxy(代理):
- Proxy是Kubernetes的网络代理组件,负责为Pod提供网络代理和负载均衡功能。
- 它维护集群内部流量的路由规则,并将请求转发到适当的Pod。
- Proxy使用IPVS或iptables等技术实现负载均衡,以确保请求能够正确地路由到运行的Pod。
- Scheduler(调度器):
- Scheduler是Kubernetes的调度器组件,负责将新创建的Pod分配给集群中的节点。
- 它根据各种策略(如资源需求、节点亲和性等)评估可用节点,并选择最适合的节点来运行Pod。
- Scheduler帮助实现Pod的均衡分布和高效利用集群资源。
- CNI(Container Network Interface):
- CNI是Kubernetes的网络插件规范,用于管理和配置容器网络。
- CNI插件负责为Pod创建和管理网络接口,并处理网络规则和路由等配置。
- CNI插件可以与不同的网络实现(如flannel、Calico等)集成,以提供容器之间和容器与外部网络之间的通信
namespace
对于生产集群,请考虑不要使用
default名字空间,而是创建其他名字空间来使用。
名字空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。当需要名字空间提供的功能时,请开始使用它们。
名字空间为名称提供了一个范围。资源的名称需要在名字空间内是唯一的,但不能跨名字空间。 名字空间不能相互嵌套,每个 Kubernetes 资源只能在一个名字空间中。
不必使用多个名字空间来分隔仅仅轻微不同的资源,例如同一软件的不同版本: 应该使用标签来区分同一名字空间中的不同资源。
Deployments
- Deployment是Kubernetes中的一个高级控制器,用于管理应用程序的部署和更新;
- 它提供了声明性的方式来定义和管理Pod的副本集,并支持滚动更新和回滚操作;
- Deployment确保指定的Pod副本数量运行在集群中,并处理故障恢复和扩缩容等任务;
一些指令
- 查看Deployment上线状态:
kubectl rollout status xxx - 更新Deployment:
kubectl set image deployment/xxx或者kubectl edit deployment/xxx- 指令后面加上
--record会将当前命令记录到revision记录中,这样我们就可以知道每个revision对应的是哪个配置文件
- 指令后面加上
- 查看上线状态:
kubectl rollout status deployment/xxx - 查看更新操作:
kubectl get rs - 检查Deployment修订历史:
kubectl rollout history deployment xxx - 查看修订历史的详细信息:
kubectl rollout history deployment xxx --revision 2 - 回滚之前的修订版本:
kubectl rollout ubdo deployment xxx- 默认情况下,如果不加
--to-revision=版本号,默认回退到上一个版本;
- 默认情况下,如果不加
- 缩放Deployment:
kubectl scale deployment xxx --replicas=10或水平自动缩放kubectl autoscale deployment xxx --min=10 --max=15 --cpu-percent=80 - 比例缩放:使用比例缩放时,可以将额外的副本分布到所有ReplicaSet,较大比例的副本会被添加到拥有最多副本的ReplicaSets,而较低比例的副本会进入到副本较少的ReplicaSet;所有剩下的副本都会添加到副本最多的ReplicaSet,具有零副本的ReplicaSet不会被扩容;
- 暂停上线:
kubectl rollout pause deployment xxx
注:Deployment确保在更新时仅关闭一定数量的Pod,默认情况下,它至少确保所需的Pod的75%处于运行状态(最大不可用比例为25%),当 Deployment 设置为 4 个副本时,Pod 的个数会介于 3 和 5 之间。
HorizontalPodAutoscaler
滚动升级时扩缩:
允许在Deployment上执行滚动更新,Deployment管理下层的ReplicaSet,配置自动扩缩时,要为每个Deployment绑定一个HorizontalPodAutoscaler,以此来管理ReplicaSet字段
扩缩策略
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60periodSeconds 表示在过去的多长时间内要求策略值为真。 你可以设置 periodSeconds 的最大值为 1800(半小时)。 第一个策略(Pods)允许在一分钟内最多缩容 4 个副本。第二个策略(Percent) 允许在一分钟内最多缩容当前副本个数的百分之十;
由于默认情况下会选择容许更大程度作出变更的策略,只有 Pod 副本数大于 40 时, 第二个策略才会被采用。如果副本数为 40 或者更少,则应用第一个策略。 例如,如果有 80 个副本,并且目标必须缩小到 10 个副本,那么在第一步中将减少 8 个副本。 在下一轮迭代中,当副本的数量为 72 时,10% 的 Pod 数为 7.2,但是这个数字向上取整为 8。 在 autoscaler 控制器的每个循环中,将根据当前副本的数量重新计算要更改的 Pod 数量。 当副本数量低于 40 时,应用第一个策略(Pods),一次减少 4 个副本;
可以限制缩容速率,禁用缩容
基于多向度量指标和自定义度量指标自动扩缩
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
status:
observedGeneration: 1
lastScaleTime: <some-time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0除了cpu外,还可以指定其他资源度量指标;默认情况下目前唯一支持的其他资源度量指标为内存,只要metrics.k8s.io存在,这些资源度量指标就是可用的,并且不会在不同的k8s集群中改变名称;
除了百分比,还可以使用绝对数值来指定资源度量指标,需要将 target.type 从 Utilization 替换成 AverageValue,同时设置 target.averageValue 而非 target.averageUtilization 的值;
还有两种其他类型的度量指标(自定义度量指标):Pod度量指标和Object度量指标,这些指标可能具有特定于集群的名称,并且需要更高级的集群监控设置;
Pod 度量指标:这些指标从某一方面描述了 Pod, 在不同 Pod 之间进行平均,并通过与一个目标值比对来确定副本的数量。 它们的工作方式与资源度量指标非常相像,只是它们仅支持 target 类型为 AverageValue:
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1kObject度量指标:用于描述在相同名字空间中的别的对象,而非 Pod,它们仅用于描述这些对象。 对象度量指标支持的 target 类型包括 Value 和 AverageValue。 如果是 Value 类型,target 值将直接与 API 返回的度量指标比较, 而对于 AverageValue 类型,API 返回的度量值将按照 Pod 数量拆分, 然后再与 target 值比较。 下面的 YAML 文件展示了一个表示 requests-per-second 的度量指标:
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 2kYAML文件字段解释
- Init Contianer类型的容器,都会比
spec.containers定义的容器先启动;并且Init Container类型的容器会按顺序逐一启动;